How Back End Read Values Sent by Front End Java Example
- Introduction
- The General-Purpose API Gateway
- Introducing The Backend For Frontend
- How Many?
- Handling Multiple Downstream Calls
- And Reuse
- For Desktop Web & Other Devices
- And Autonomy
- General Perimeter Concerns
- When To Use
- Farther Reading
- Conclusion
Introduction
With the advent and success of the web, the de facto way of delivering user interfaces has shifted from thick-client applications to interfaces delivered via the spider web, a trend that has also enabled the growth of SAAS-based solutions in general. The benefits of delivering a user interface over the web were huge - primarily as the price of releasing new functionality was significantly reduced as the cost of client-side installs was (in most cases) eliminated altogether.
This simpler world didn't last long though, every bit the age of the mobile followed before long afterwards. Now nosotros had a problem. We had server-side functionality which we wanted to expose both via our desktop spider web UI, and via one or more mobile UIs. With a system that had initially been developed with a desktop-web UI in mind, we oft faced a trouble in all-around these new types of user interface, frequently every bit we already had a tight coupling between the desktop web UI and our backed services.
The General-Purpose API Backend
A first pace in accommodating more than than one blazon of UI is unremarkably to provide a single, server-side API, and add together more functionality as required over fourth dimension to back up new types of mobile interaction:
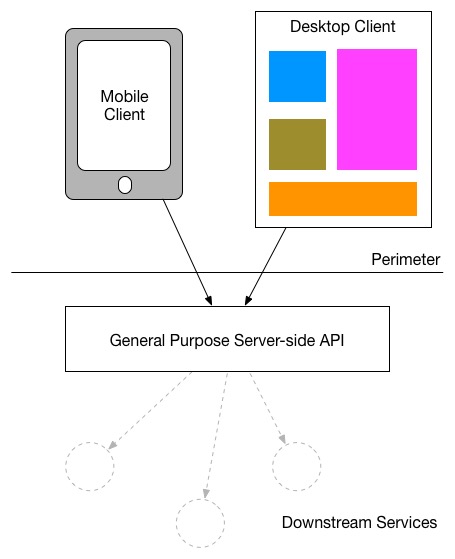
If these different UIs want to make the same or very similar sorts of calls, then it can be piece of cake for this sort of general-purpose API to be successful. However the nature of a mobile experience often differs drastically from a desktop web experience. Firstly, the affordances of a mobile device are very dissimilar. We take less screen real manor, which means nosotros can display less data. Opening lots of connections to server-side resources tin can bleed bombardment life and limited data plans. And secondly, the nature of the interactions we want to provide on a mobile device tin differ drastically. Think of a typical bricks-and-mortar retailer. On a desktop app I might permit you to wait at the items for sale, order online or reserve in store. On the mobile device though I might desire to permit yous scan bar codes to practise price comparisons or give you context-based offers while in store. As we've built more than and more mobile applications nosotros've come up to realise that people use them very differently and therefore the functionality we demand to expose will differ too.
So in do, our mobile devices volition want to make unlike calls, fewer calls, and volition desire to brandish different (and probably less) data than their desktop counterparts. This means that we need to add boosted functionality to our API backend to support our mobile interfaces.
Another trouble with the general-purpose API backend is that they are past definition providing functionality to multiple, user-facing applications. This ways that the unmarried API backend can go a bottleneck when rolling out new delivery, equally so many changes are trying to be fabricated to the same deployable antiquity.
The tendency for the full general-purpose API backend to have on multiple responsibilities, and therefore require lots of work, often results in a team being created specifically to handle this code base. This tin can make the problem much worse, equally at present front-end teams accept to interface with a divide squad to get changes made - a team which will have to balance both the priorities of the unlike client teams, and also work with multiple downstream teams to swallow new APIs equally they become available. It could be argued that at this point we accept merely created a smart-slice of middleware in our architecture, something which is non focused on any item business organization domain - something which goes against many people'south views of what sensible Service Oriented Architecture should look similar.
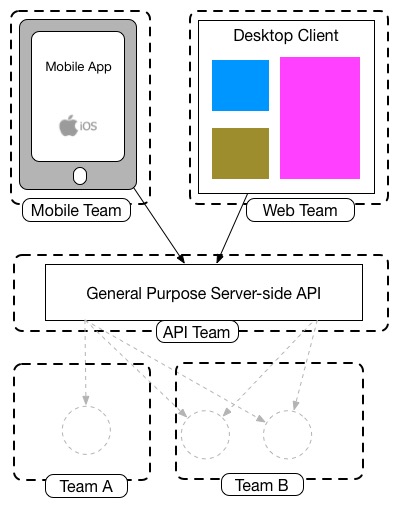
Introducing The Backend For Frontend
One solution to this problem that I have seen in use at both REA and SoundCloud is that rather than have a general-purpose API backend, instead you have one backend per user experience - or as (ex-SoundClouder) Phil Calçado chosen it a Backend For Frontend (BFF). Conceptually, you should recollect of the user-facing application as being two components - a client-side application living outside your perimeter, and a server-side component (the BFF) within your perimeter.
The BFF is tightly coupled to a specific user experience, and will typically exist maintained by the same team as the user interface, thereby making it easier to define and adapt the API as the UI requires, while as well simplifying process of lining up release of both the customer and server components.
The BFF is tightly focused on a single UI, and just that UI. That allows it to be focused, and volition therefore be smaller.
How Many BFFs?
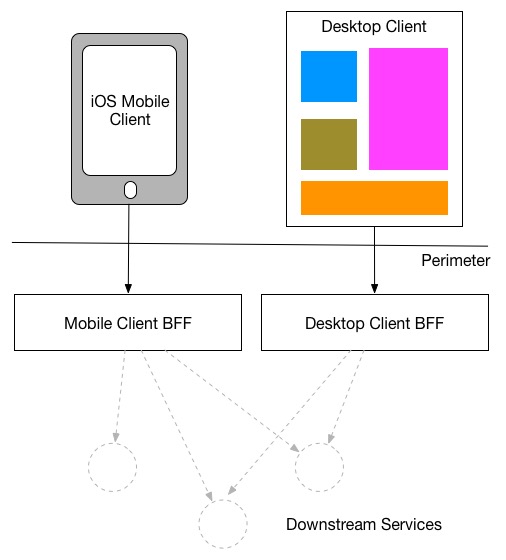
When information technology comes to delivering the same (or similar) user experience on different platforms, I take seen 2 different approaches. The model I prefer is to strictly have a unmarried BFF for each unlike type of client - this is a model I saw used at REA:
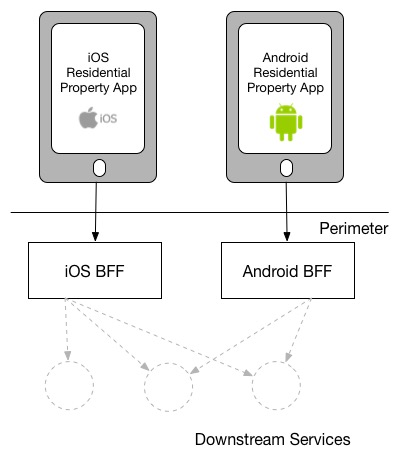
The other model, which I have seen in utilise at SoundCloud, uses one BFF per type of user interface. So both the Android and iOS versions of the listener native application apply the same BFF:
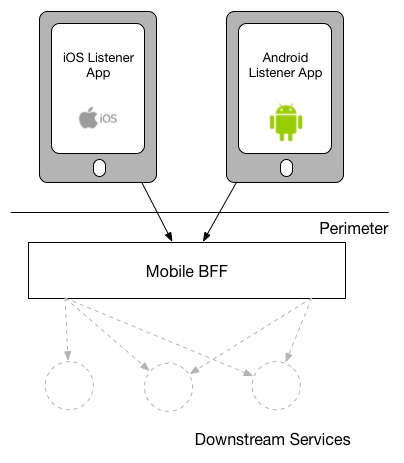
My primary business with the 2d model is just that the more types of clients you have using a single BFF, the more temptation there may be for it to become bloated past handling multiple concerns. The key thing to sympathize here though is that even when sharing a BFF, it is for the same grade of user interface - and then while SoundCloud's listener Native applications for both iOS and Android use the aforementioned BFF, other native applications would use dissimilar BFFs (for example the new Creator awarding Pulse uses a different BFF). I'k also more relaxed about using this model if the same team owns both the Android and iOS applications and own the BFF besides - if these applications are maintained by unlike teams, I'm more inclined to recommend the more strict model. So you can meet your organisation structure as existence one of the main drivers to which model makes the near sense (Conway's Constabulary wins once again). It'southward worth noting that the SoundCloud engineers I spoke to suggested that having ane BFF for both Android and iOS listener applications was something they might reconsider if making the conclusion again today.
One guideline that I actually like from Stewart Gleadow (who in turn credited Phil Calçado and Mustafa Sezgin) was 'one experience, one BFF'. So if the iOS and Android experiences are very similar, and then it is easier to justify having a unmarried BFF. If however they diverge greatly, and so having carve up BFFs makes more sense.
Pete Hodgson made the ascertainment that BFFs work best when aligned around team boundaries, so team structure should drive how many BFFs you have. So that if you accept a single mobile squad, you lot should take i BFF, merely if you had separate iOS and Android teams, you'd have split BFFs. My business organisation is that team structures tend to exist more fluid than our organisation design. So if you accept a single BFF for mobile, so carve up the team into iOS and Android specialisations, practise you then have to split the BFF likewise? If the BFFs were already separate, then splitting the team would be easier as you can reassign ownership of the already independent asset. The interplay of BFF and squad structure is of import though, something nosotros'll explore more shortly.
Ofttimes the driver towards having a smaller number of BFFs is around reusing server-side functionality to avoid too much duplication, merely there are other ways to handle this which nosotros'll cover shortly.
And Multiple Downstream Services (Microservices!)
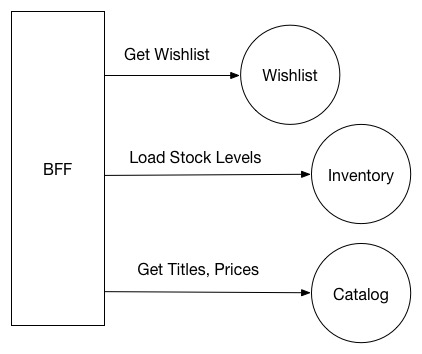
BFFs tin be a useful pattern for architectures where there are a modest number of backend services. For organisations using a large number of services however they can be essential, as the demand to aggregate multiple downstream calls to evangelize user functionality increases drastically. In such situations it will be mutual for a single call in to a BFF to consequence in multiple downstream calls to microservices. For example, imagine an awarding for an due east-commerce company. Nosotros want to pull back a list of items in a user's wish list, displaying stock levels, and price:
| The Brakes - Requite Claret | In Stock! (xiv items remaining) | $5.99 | Club At present |
| Bluish Juice - Retrospectable | Out Of Stock | $17.50 | Pre Order |
| Hot Chip - Why Make Sense? | Going fast (two items left) | $ix.99 | Order At present |
Multiple services agree the pieces of information nosotros want. The Wishlist service stores information nearly the list, and IDs of each detail. The Catalog service stores the name and toll of each item, and the Stock levels are stored in our inventory service. And so in our BFF nosotros'd betrayal a method for retrieving the full playlist, which would consist of at least 3 calls:
From an efficiency betoken of view, it would be much smarter to run every bit many calls in parallel as possible. Once the initial phone call to the Wishlist service completes, ideally we'd like to so run the calls to the other services at the aforementioned time to reduce the overall telephone call time. This need to mix calls that we want to run in parallel vs those that run in sequence can quickly become painful to manage, especially for more complex scenarios. This is one area where a reactive style of programming can help (such as that provided by RxJava or Finagle's futures organisation) as the composition of multiple calls becomes easier to manage.
Failure modes though become of import to sympathise. In our example above, we could insist that all downstream calls take to return in gild for the states to return a payload to our client. However is this sensible? Obviously we tin can't do anything if the Wishlist service is down, but if only the Inventory service was downwardly, wouldn't it exist better to just dethrone the functionality nosotros pass back to the customer, maybe just by removing the stock level indicator? These concerns have to be managed past the BFF itself in the first instance, but nosotros also need to make sure that the customer making the telephone call to the BFF tin can interpret a partial response and render it correctly.
Reuse and BFFs
Ane of the concerns of having a single BFF per user interface is that you can stop upward with lots of duplication betwixt the BFFs themselves. For example they may finish up performing the same types of assemblage, have the same or similar code for interfacing with downstream services etc. Some people react to this by wanting to merge these back together, and so take a general-purpose aggregating Border API service. This model has proven time and again to lead to highly bloated lawmaking with multiple concerns squashed together.
Equally I have said many times before, I am fairly relaxed almost duplicated code across services. Which is to say that while in a single process boundary I will typically do any I can to refactor out duplication into suitable abstractions, I don't have the same reaction when confronted by duplication across services. This is mostly as I am ofttimes more than worried about the potential for extracting shared code to lead to tight coupling betwixt services - something I am more than worried almost than duplication in general. That said, in that location are certainly cases where this is warranted.
My colleague Pete Hodgson has pointed out that when you don't have BFFs, then ofttimes the 'common' logic ends upward existence baked into the different clients themselves. Due to the fact that these clients use very dissimilar engineering stacks, identifying the fact that this duplication is occurring can be difficult. With organisations tending to have a mutual technology stack for server-side components, having multiple BFFs with duplication may exist easier to spot and factor out.
When the time does arise to excerpt shared code, there are two obvious options. The outset, which is often cheapest merely more fraught, is to excerpt a shared library of some sort. The reason this tin be problematic is that shared libraries are a prime number source of coupling, particularly when used to generate client-libraries for calling downstream services. Nonetheless there are situations where this feels correct - especially when the code beingness abstracted is purely a business concern inside the service.
The other option is to excerpt out the shared functionality in a new service, which can work well if you tin conceptualise the new service has something modeled effectually the domain in question.
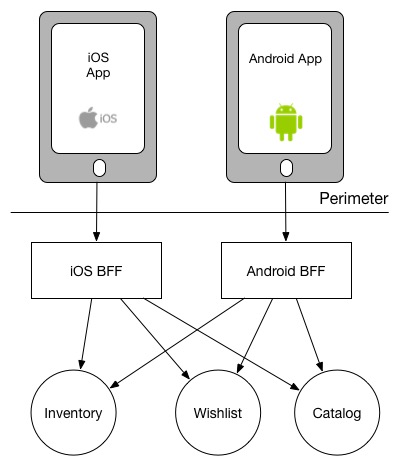
A variation of this approach might exist to push button aggregation responsibilities to services farther downstream. Accept the example in a higher place where we discussed rendering of a wish list. Let's imagine we are rendering a wishlist in 2 places - on Android, iOS Web. Each of our BFFs are making the same three calls:
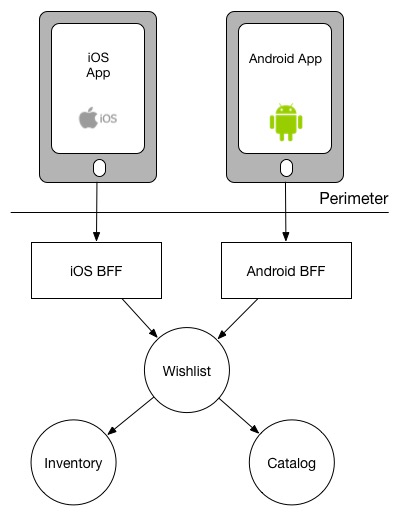
Instead, nosotros could alter the Wishlist service to make the downstream calls for us, thereby simplifying the task for the callers:
I accept to say that the same code being used in two places wouldn't necessarily cause me to want to excerpt out a service in this way, but I'd be certainly considering it if the transaction price of creating a new service was low enough, or I was using it in more than a couple of places (for case maybe on the desktop web). I recall the onetime aphorism of creating an abstraction when you're about to implement something for the 3rd fourth dimension still feels like a good rule of thumb, even at the service level.
BFFs for Desktop Web and Beyond
You tin remember of BFFs as just having a utilize in solving the constraints of mobile devices. The desktop spider web experience is typically delivered on more powerful devices with improve connectivity, where the price of making multiple downstream calls is manageable. This tin permit your web application to make multiple calls directly to downstream services without the need for a BFF.
I have seen situations though where the utilize of a BFF for the spider web too can be useful. When you lot are generating a larger portion of the spider web UI on the server-side (e.yard using server-side templating), a BFF is the obvious place where this can exist done. It can also simplify caching somewhat as you can place a contrary proxy in forepart of the BFF, allowing you to enshroud the results of aggregated calls (although y'all have to brand sure y'all ready your cache controls accordingly to ensure that the aggregated content's expiry is as brusk every bit the freshest piece of content in the aggregation needs it to be). I've seen it used multiple times in fact without calling it a BFF - in fact the general-purpose API backend often grows from such a fauna.
I've seen at to the lowest degree i organization utilise BFFs for other external parties that need to brand calls. Coming back to my perennial case of a music shop, I might expose a BFF to allow third parties to extract royalty payment information, provide Facebook integration or allow streaming to a range of prepare-top box devices:
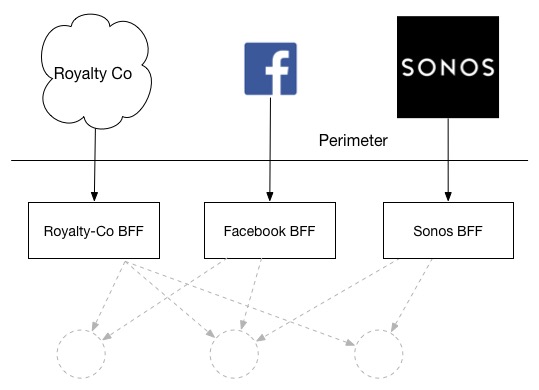
This approach can be especially effective as third-parties ofttimes have express to no ability (or want) to employ or change the API calls they make. With a general-purpose API backend, you may have to keep old versions of the API around just to satisfy a small subset of your outside parties unable to make a change - with BFF this problem is essentially reduced.
And Autonomy
Quite oftentimes we come across situation where one team is working on a frontend, and a different team is creating the backend services. In general, we're trying to avoid this by moving to microservices which are aligned around business verticals, merely even and so there are situations where this is hard to avert. Firstly, at a certain level of scale or complexity, multiple teams need to go involved. Secondly, the depth of technical skills required to execute a good Android or iOS experience often need specialised teams.
So teams building user interfaces are confronted with the situation that they are calling an API which another team is driving, and often than API is evolving while the user interface is being adult. The BFF tin can help hither, particularly if information technology is owned past the team creating the user interface. They evolve the API of the BFF at the same fourth dimension every bit creating the front end end. They tin can iterate both quickly. The BFF itself nevertheless needs to call the other downstream services, but this can be done without having to interrupt evolution of the user interface.
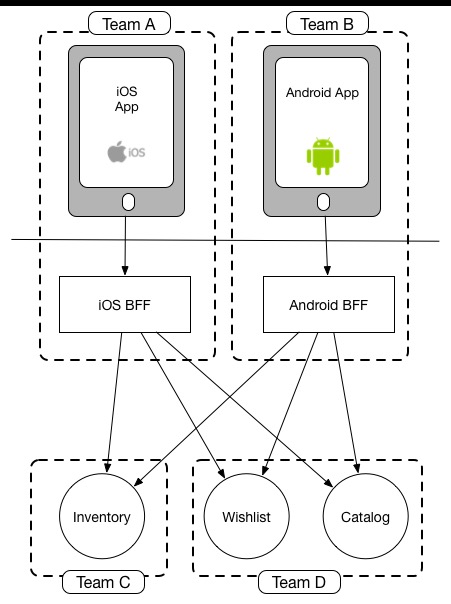
The other do good of using a BFF aligned along team boundaries like this is that the squad creating the interface can be much more than fluid in thinking about where functionality lives. For example they could decide to push functionality on to the server-side to promote reuse in the hereafter and simplify a native mobile application, or to allow for the faster release of new functionality (as you can bypass the app store review processes). This decision is one that tin can exist made by the team in isolation if they own both the mobile application and the BFF - it doesn't crave any cross-squad coordination.
General Perimeter Concerns
Some people use BFFs to implement generic perimeter concerns, such as hallmark/authorisation or request logging. I'grand torn about this. On the one hand, much of this functionality is then generic that I'd be inclined to implement it using another layer sitting farther upstream, perhaps using something like a tier of Nginx or Apache servers. On the other hand, such an additional layer can't assistance simply add latency. BFFs are oft used in microservice environs where we are already very sensitive virtually latency due to the high number of network calls beingness made. As well, the more layers you have to deploy to make a production-like stack can brand evolution and test more circuitous - having all of these concerns inside the BFF as a more self-contained solution can be attractive every bit a result:
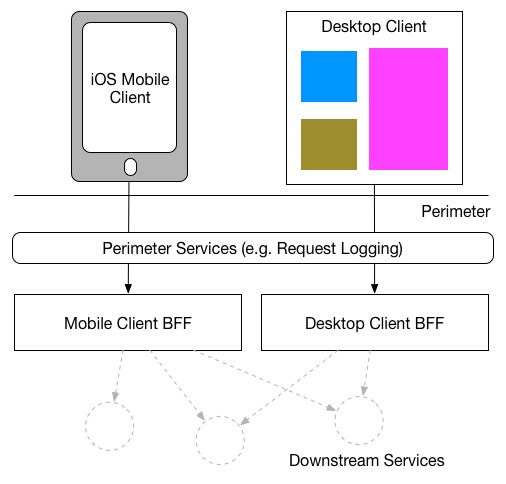
Every bit nosotros discussed earlier, another way to factor out this duplication could be to use a shared library. Assuming your BFFs are using the same technology, this shouldn't be as well difficult, although the usual caveats almost shared libraries in a microservice architecture apply.
When To Employ
For an application which is merely providing a web UI, I suspect a BFF volition only brand sense if and when you have a meaning amount of aggregation required on the server-side. Otherwise, I think other UI composition techniques can work only as well without requiring an boosted server-side component (I'll hopefully talk about those soon).
The moment that yous need to provide specific functionality for a mobile UI or 3rd political party though, I would strongly consider using a BFFs for each party from the first. I might reconsider if the price of deploying additional services is high, but the separation of concerns that a BFF can bring brand information technology a fairly compelling proffer in most cases. I'd be even more inclined to apply a BFF if in that location is a significant separation betwixt the people building the UI and downstream services, for reasons outlined above.
Further Reading (And Viewing)
- Since I wrote this piece, Lukasz Plotnicki from ThoughtWorks has published a cracking article on SoundCloud's use of the BFF pattern
- Lukasz being interviewed about the pattern (and other things) on a recent episode of the Software Engineering Podcast.
- Bora Tunca from SoundCloud as well goes into more than item during a talk at microxchg 2016.
Conclusion
Backends For Frontends solve a pressing concern for mobile development when using microservices. In improver they provide a compelling alternative to the general-purpose API backend, and many teams make use of them for purposes other than only mobile development. The simple act of limiting the number of consumers they back up makes them much easier to work with and change, and helps teams developing client-facing applications retain more than autonomy.
Thanks go to Matthias Käppler, Michael England, Phil Calçado, Lukasz Plotnicki, Jon Eaves, Stewart Gleadow and Kristof Adriaenssens for their assistance in researching this article, and Giles Alexander, Ken McCormack, Sriram Viswanathan, Kornelis Sietsma, Hany Elemary, Martin Fowler, Vladimir Sneblic, and Pete Hodgson for general feedback. I'd really appreciate any further feedback also, then feel complimentary to leave a comment beneath!
Meet more patterns.
Source: https://samnewman.io/patterns/architectural/bff/
0 Response to "How Back End Read Values Sent by Front End Java Example"
Post a Comment